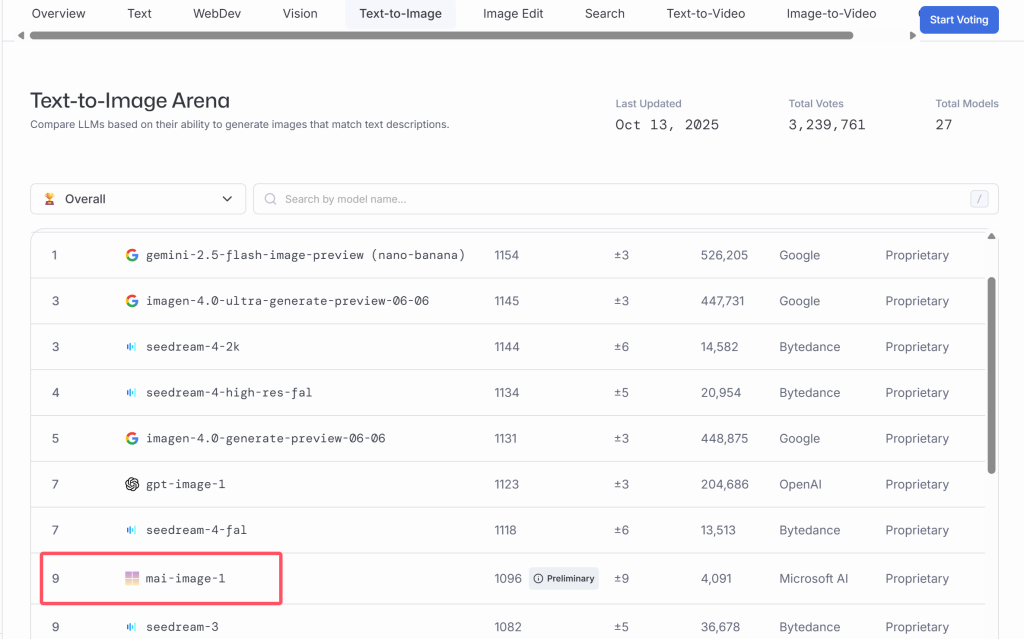
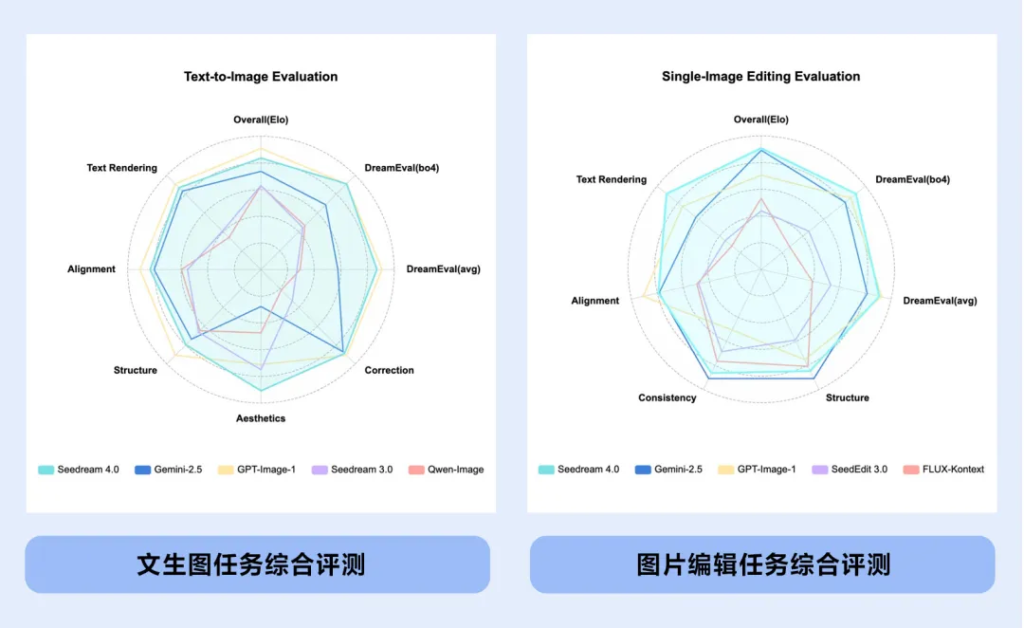
2025年8 月5日,Qwen 团队正式发布了开源图像生成基础模型 Qwen‑Image,这一超 200 亿参数规模的 MMDiT 模型,在复杂文本渲染与图像编辑能力方面实现显著突破。本文将带你从技术原理、功能亮点、应用场景等维度完整了解 Qwen‑Image 所代表的 AI 图像生成新高度。

一、Qwen‑Image 是什么?
Qwen‑Image 是阿里巴巴 Qwen 系列首次推出的开源文本生成图像基础模型,参数规模为 20B,许可为 Apache‑2.0 开源协议,可在 Hugging Face 和 ModelScope 获取。它采用 MMDiT 架构,专注于高精度的文本渲染和图像编辑能力。
二、核心功能与技术优势
- 复杂文本渲染能力强:支持中英文多行布局、字符级视觉一致性,在 LongText-Bench、ChineseWord、TextCraft 等 benchmark 上表现优异。
- 卓越图像编辑能力:支持文本→图生成、图像重构、风格迁移、对象插入与删除,兼顾语义一致性与视觉美感。
- 跨任务性能领先:在 GenEval、DPG、OneIG-Bench、GEdit、ImgEdit、GSO 等 benchmark 上多项指标领先。
- 高度兼容生态:可通过 ComfyUI、diffusers 等框架加载使用,支持 LoRA 微调与 FP8 量化推理。

三、模型使用体验与集成方式
Qwen‑Image 可通过 chat.qwen.ai 中 “Image Generation” 功能免费在线体验。:
本地部署支持如下方式:
- 使用 diffusers 安装 FluxPipeline 并加载 Qwen‑Image 模型。
- 通过 ComfyUI 插件直接调用模型,设置分辨率、CFG、步数等参数生成图像。
- 支持 FP8/GGUF 等轻量量化格式,在低显存环境下实现高效推理。
四、典型应用场景
- 中文海报设计:高保真渲染中文文字、复杂多段落布局,适合海报与插画创作。
- 数据可视化与信息图:生成具备结构性视觉带文本元素的不锈信息图或流程图。
- 图像编辑与改造:支持细粒度风格改变、文件局部编辑与文字替换等操作。
- 海报与 UI 原型生成:特别适合快速草绘视觉作品和界面原型。
五、使用时需注意的限制
- 剩余编辑版尚未发布:目前仅公开基础生成模型,专用图像编辑版本仍在计划中发布。
- 上下文长度挑战:虽可处理长文本布局,但在极长结构中仍可能出现拼接或排版混乱的情况。
- 依赖提示设计质量:复杂 prompt 输出依赖提示设计,对细节问题敏感。
六、Qwen‑Image 在 AI 图像生态中的地位
作为国内首个开源支持中文高保真文本渲染的图像模型,Qwen‑Image 既可媲美 GPT‑4o,也优于许多现有中文图像模型,其开源力度与技术表现受到行业广泛关注。
未来预计通过 LoRA fine‑tune、增强训练、编辑模型发布等方式进一步完善其应用生态(如 vLLM、WaveSpeed、DiffSynth 等平台已快速支持)。
总结
Qwen‑Image 不仅是 Qwen 系列的重要升级,也为开源图像生成设定了新的标准。它在复杂文本渲染、图像编辑、语言支持、多任务性能方面体现出卓越能力。