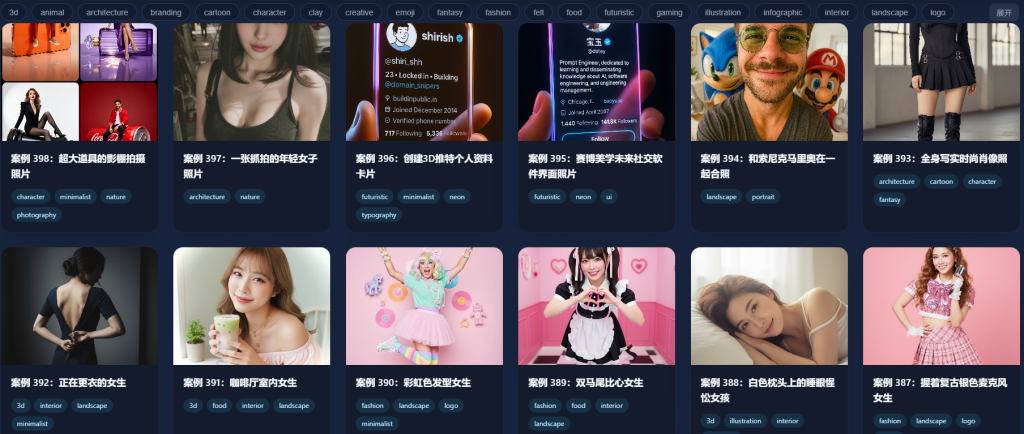
腾讯混元团队近日正式开源了其高效的文本到图像生成模型 HunyuanImage 2.1。该模型支持原生 **2K(2048×2048)**分辨率图像输出,标志着开源AI在高分辨率创作领域取得了重大进步。目前,模型代码和权重已在 Hugging Face 和 GitHub 平台全面开放,为全球开发者提供了新的工具。

核心功能:原生2K高清与复杂提示支持
HunyuanImage 2.1 的最大亮点在于其在保持高生成效率的同时,能够输出细节丰富、语义一致的 2K 高清图像。这得益于其优化的结构化描述和大规模数据集训练,使得模型能够实现更强的文本-图像对齐能力。
此外,该模型支持最长 1000 token 的复杂提示词,能精准控制单图中多个主体的姿势、表情和场景布局,有效避免了传统AI模型中常见的“内容漂移”问题。例如,用户可以通过一个长提示词,描述一个包含多个角色和复杂动作的场景,模型也能生成高度协调的画面。
模型还原生支持中英文混合提示词,并内置提示词增强机制,进一步提升了生成结果的一致性和创意性。在跨场景泛化上,它能处理复杂的物理规律和三维空间语境,增强了图像的真实感和美观度。
多场景应用与生成效率
HunyuanImage 2.1 不仅在图像质量上有所突破,也在实用功能和效率方面进行了优化:
- 文本嵌入: 该模型支持将文字无缝嵌入到生成的图像中,用户可自定义字体、位置和风格,非常适合制作带有标题的书籍封面、宣传海报和社交媒体插图等商业设计内容。
- 高效生成: 尽管分辨率提升至 2K,模型的生成速度与处理 1K 图像相当,仅需数秒即可完成。这显著降低了计算资源消耗,使其在资源有限的环境中也能高效运行。
性能评估与开源价值
在专业评估中,HunyuanImage 2.1 在语义对齐、细节控制和多对象生成等多个维度上获得了高分。其性能与闭源模型 Seedream 3.0 接近,并在开源模型中超越了 Qwen-Image。超过100位专业评估者的测试结果表明,HunyuanImage 2.1 的图像质量已达到商业级水准。
腾讯此次开源HunyuanImage 2.1,旨在推动AI生态发展,通过开放模型权重和代码,鼓励全球开发者进行自定义微调和创新应用。这一举措有望吸引更多开发者加入社区,进一步巩固腾讯在开源AI图像生成领域的地位。