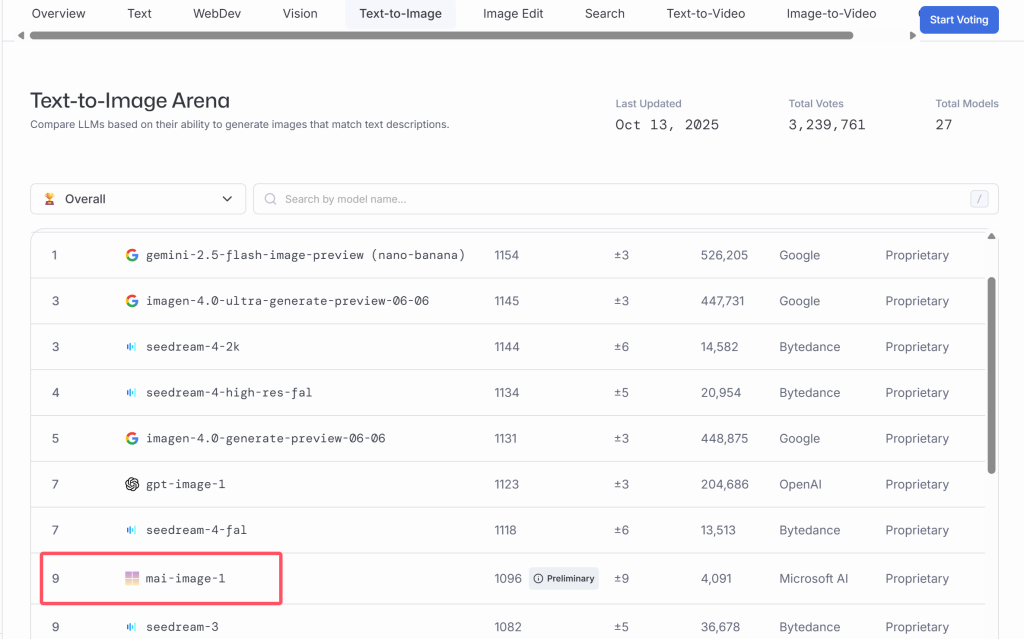
1. VibeVoice 是什么?
VibeVoice 是微软研究团队推出的开源文本转语音(TTS)框架,核心目标是从文本直接生成富有表现力的、长篇幅、多说话人的对话式音频(例如播客)。它强调在真实对话中的说话人一致性与自然轮替,支持最长约90 分钟的连续合成与最多 4 位说话人,并提供跨语言(英/中)与一定程度的情感、唱段表达能力(研究预览性质)。
2. 为什么值得关注:它解决了哪些痛点?
- 长时段对话合成能力:突破传统 TTS 在长序列上的计算与稳定性瓶颈,可生成小时级别的对话音频。
- 多说话人协同:在同一段音频中保持多位角色的音色与风格一致,提升播客、剧本对话、教学解说等场景的可用性。
- 表达更自然:在轮到讲话与停顿衔接上更接近真实交流,降低“机器感”。
- 开放与可复现:项目代码与模型以开源方式发布,便于研究与二次开发(遵循许可与使用规范)。
3. 基础用法与典型场景
- 播客/剧本对话合成:从文本大纲直接合成多角色对话,适合内容创作者快速出样与打磨台本。
- 课程与教程音频:用多角色演绎复杂概念(讲解者 + 提问者),提升听感与信息密度。
- 跨语言演示:英/中文内容的互译式呈现与朗读(研究性质),用于对照学习或多语言预演。
- 情感化表达:在解说、访谈、故事讲述中加入更自然的停连与语气变化。
4. 模型与技术要点
- 连续语音标记器(Tokenizer):采用声学与语义双标记器,以约 7.5 Hz 的超低帧率工作,在保真与计算效率间取得平衡。相较常见方案(如 Encodec),报告称在压缩率上有数量级提升(研究结果)。
- Next-Token Diffusion:结合大语言模型理解对话上下文,以扩散头生成高保真声学细节,实现长序列合成的稳定输出。
- 模型规模与上下文:当前公开的
VibeVoice-1.5B版本面向研究使用,支持约 64K 上下文与最长约 90 分钟、最多 4 说话人的合成;另有预览与流式方向的版本线。 - 语言与能力范围:主要面向英文与中文的语音合成;聚焦语音而非背景音乐与复杂声场。
5. 隐私、安全与合规边界
- 研究用途为主:官方建议以研究与开发为主要使用目的,谨慎用于生产场景。
- 限制与禁用场景:不适用于未经明确录音同意的声音拟声/冒用,不支持实时低延迟转换等高风险用途。
- 可溯源与披露:模型卡强调在输出中嵌入可听的 AI 生成提示与不可感知水印以辅助来源校验,分享时也建议显著披露“由 AI 生成”。
- 语言与内容边界:当前仅针对英/中文训练,其他语言输出可能不可用或不稳定;聚焦语音,不用于背景音乐/音效生成。
6. 常见问题(FAQ)
Q1:最长能生成多长?
A:当前研究版本可达约 90 分钟的连续合成(具体取决于上下文设置与推理配置)。
Q2:最多支持多少位说话人?
A:官方演示与文档显示可达最多 4 位。
Q3:是否支持中文?
A:模型主要针对英文与中文训练,其他语言不在当前支持范围。
Q4:能否商用或用于生产系统?
A:模型卡建议以研究与开发为主,若用于生产需进行额外评估并遵循许可与法律法规。
Q5:是否会插入提示音或水印?
A:是。模型卡说明生成音频包含可听提示与不可感知水印以便来源验证。