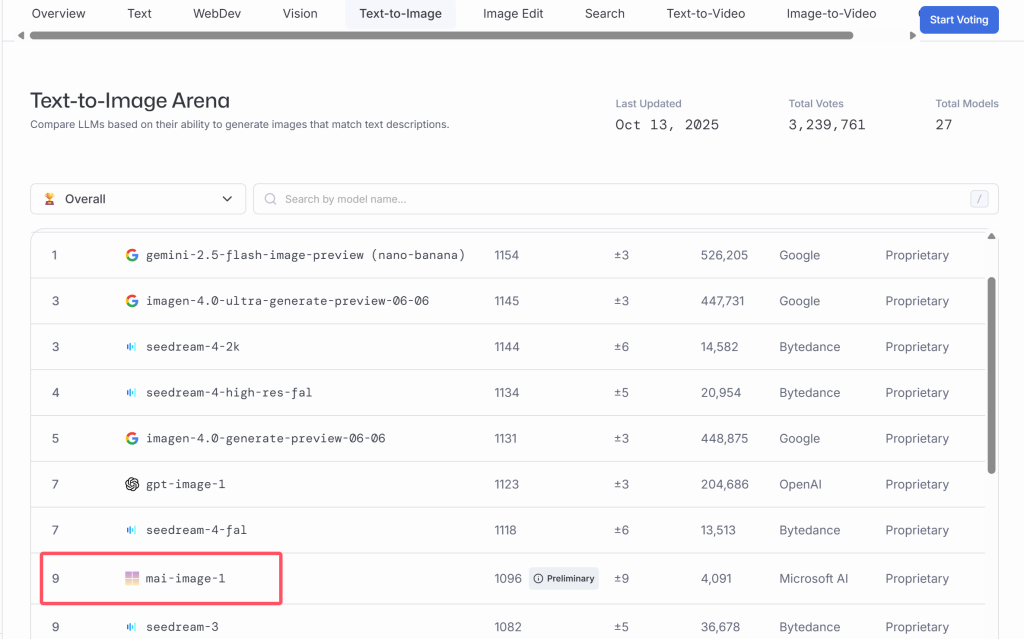
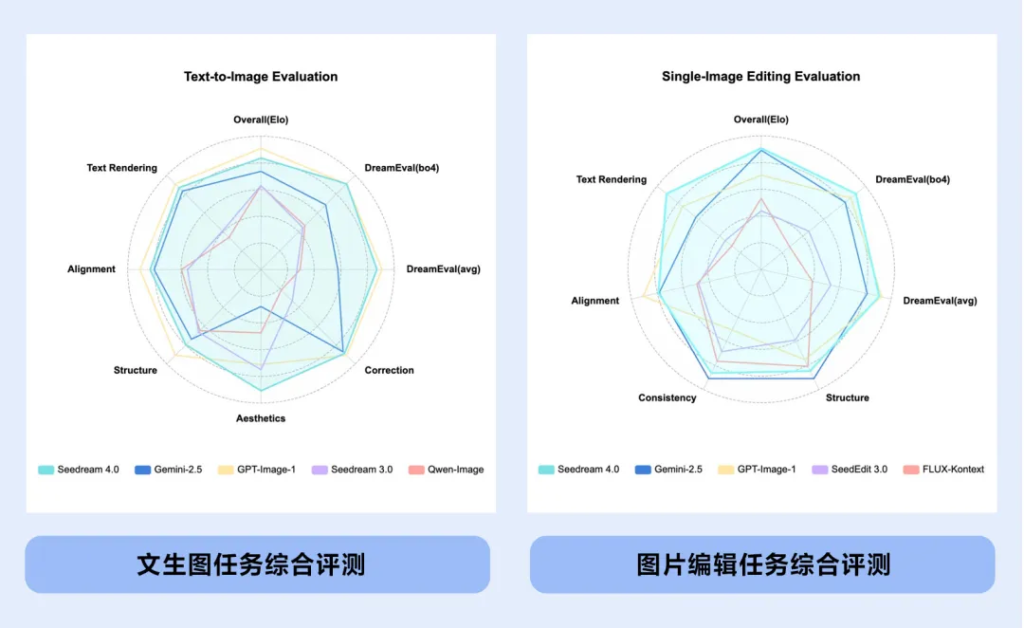
文章目录
1. SpatialLM 1.5 是什么?
SpatialLM 1.5 可理解为一类“空间语言模型”:它尝试把 自然语言 与 三维世界 建立起对齐关系,从而理解“物体在何处”“与谁相邻”“如何到达”等与空间相关的指令或问题。与传统只处理文本或二维图像的模型不同,SpatialLM 1.5 的关注点在于把语言中的空间线索映射到可计算的三维表达(如点云、体素、场景图等),并据此进行定位、推理与交互。

2. 为什么值得关注:它解决了什么问题?
- 语言与三维的脱节:人类指令常包含位置、方向、拓扑关系等空间信息;传统模型难以在三维环境中准确落地。
- 全链路理解需求:从“听懂”到“找到/移动/操作”,需要语言理解、环境建模和动作规划协同工作。
- 类通用交互接口:通过自然语言与三维场景交互,有望降低机器人、AR/VR 等系统的人机沟通门槛。
3. 它如何“听懂”空间:工作原理概览
以下为高层抽象,具体实现以官方技术报告为准。
- 多模态对齐:将文本与三维数据(例如 RGB-D、点云、网格或重建体)对齐到统一的表示空间,形成语言条件下的空间表征。
- 空间标注与引用:通过“参照消解(referential grounding)”把“那个靠窗的椅子”等自然表达映射为场景中的具体对象或区域。
- 拓扑/几何关系建模:学习“上/下/左/右、前/后、内/外、相邻/包含”等空间关系,并在坐标系或场景图中进行推理。
- 记忆与一致性:跨视角、跨时刻整合信息,维持“世界记忆”,以应对遮挡、移动和视角变化。
- 任务指令解析:将“去到冰箱旁边”“把桌上红色杯子放到水槽左边”解析为可执行的中间步骤或目标条件。
4. 能做什么:能力与示例任务
- 三维参照理解:根据自然语言在场景中定位物体或区域,例如“书架最上层,靠右的蓝色盒子”。
- 空间问答(3D VQA):回答关于房间布局、物体关系、可达性等问题,例如“从门口到沙发需要经过哪些区域?”
- 路径/动作建议:在具备下游控制模块时,提供基于语言的导航或操作提示(不等同于直接控制)。
- 场景对话与检索:支持以对话形式检索场景信息,如“窗边的插座数量是多少?”“厨房的垃圾桶在哪一侧?”
5. 应用场景与价值边界
- 机器人与家庭服务:以自然语言说明任务目标,辅助定位与导航;与高层策略或控制系统配合完成执行。
- AR/VR 与空间交互:根据用户语音在三维空间中标注、检索与高亮对象,支持信息叠加与引导。
- 数智空间管理:在商超、工厂或仓储场所,基于语言快速定位物资与通道,辅助巡检与盘点。
- 教育与科普演示:以自然语言讲解三维结构、装配关系与安全路径,降低专业门槛。
6. 对比:与传统三维理解/导航方法的不同
- 输入形式更自然:传统方法依赖几何特征与规则;SpatialLM 1.5 直接理解自然语言中的空间指示。
- 跨模态信息融合:结合图像/深度/点云与语言,提高跨视角、跨时间的鲁棒性。
- 与交互结合更紧密:支持对话式提问与澄清,便于在不确定场景下逐步缩小范围。
7. 已知限制与开放问题
- 数据与标注成本:高质量三维数据采集、标注与重建仍具有成本与技术门槛。
- 尺度与泛化:从小空间到大尺度环境的泛化能力,以及不同场景风格/光照/遮挡条件下的稳定性,是关键挑战。
- 语言歧义与细粒度定位:自然语言可能含糊,需要多轮澄清与更细粒度的空间对齐机制。
- 与下游系统衔接:要真正“动起来”,仍需与导航、控制、规划模块协同,明确责任边界与安全约束。
8. 常见问题(FAQ)
Q1:SpatialLM 1.5 是否等同于导航或控制系统?
不是。它侧重“理解与对齐”,可为下游导航/控制提供空间语义与目标描述,但不直接替代底层控制。
Q2:需要什么数据才能使用?
通常需要多视角图像、深度/点云或重建体等三维数据源;不同任务对数据精度与更新频率的要求不同。
Q3:与普通多模态大模型有何区别?
SpatialLM 强调三维语义与空间关系的理解与推理,关注“在场景中何处、如何到达”的问题,而不仅是图文匹配或问答。
Q4:是否适合直接商用?
请依据官方许可与合规要求评估;在生产环境中建议与传统几何/导航模块协同,并做好安全与容错设计。
9. 参考与资源链接
- 开源网址:GitHub地址 、Hugging Face地址 、魔搭地址
- 相关背景阅读:点云基础、SLAM 简介
- 开放数据与工具(示例):COCO、nuScenes、Waymo Open(三维理解相关,可按任务自选)
小结:SpatialLM 1.5 的核心在于把自然语言与三维世界建立可靠的语义对齐,让“描述—定位—推理”成为可能。对于机器人、AR/VR 与数智空间等场景,这一能力可作为上层交互与下层执行之间的桥梁。落地时建议从小场景验证出发,明确数据质量与安全边界,再逐步拓展到更复杂的真实环境。