在AI领域,各种评测基准层出不穷,但鲜有能让顶尖模型集体“折戟”的。近期,一个名为 FormulaOne 的全新AI评测基准横空出世,其结果令人大跌眼镜:包括 GPT-5、Grok4、o3Pro 在内的多款前沿AI模型,在测试中竟然都获得了零分!
这个由专注于超智能研究的机构 AAI 推出的基准,旨在挑战现有AI模型的极限。这一惊人的结果,不仅在科研界引发了广泛讨论,更让我们不得不重新审视:这些被誉为“最强大脑”的AI,距离真正的博士级推理能力,究竟还有多远?
FormulaOne:专为挑战AI极限而生
FormulaOne基准包含了 220个新颖的图结构动态规划问题。这些问题难度分为三个级别:中等、深层和科研级别。其涉及的领域包括拓扑、几何和组合问题,对模型的推理与逻辑推演能力提出了极高的要求,难度堪称博士级挑战。
这些问题背后的核心原理,依赖于一个名为 Courcelle 的算法元定理。该定理指出,对于每个类似树的图,任何可用逻辑定义的问题都可以通过动态规划来解决。这要求AI模型必须理解一种被称为树分解的结构,并能通过动态规划算法逐步求解,这远超了传统语言模型的能力范围。
前沿模型:浅层勉强及格,深层集体崩溃
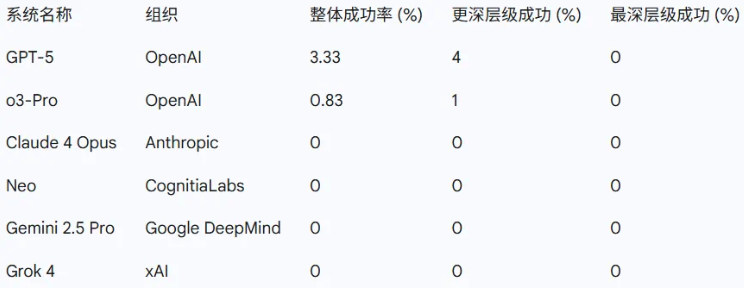
评测结果清晰地揭示了顶尖AI模型的真实能力边界:
- 浅层难度问题: 在相对简单的题目上,这些模型表现尚可,成功率在 50% 到 70% 之间。这说明它们对这类基础问题有初步的理解和解决能力。
- 深层难度问题: 随着问题难度的增加,模型的成功率急剧下降。Grok4、Gemini-Pro 等模型最多只能解出 1% 的题目,而 GPT-5Pro 的表现稍好,也仅解出了 4个 问题。
- 最深层难度问题: 在这个难度级别上,所有参与评测的模型全部失败,成功率是 零。面对真正的“博士级”挑战,AI模型集体陷入了困境。

反思与展望:AI的真正“智能”之路
FormulaOne的评测结果,无疑为AI技术的发展泼了一盆冷水,也引发了更深层次的思考:
- AI的局限性: 尽管AI在语言生成、图像识别等领域取得了巨大进步,但在面对需要高级抽象推理和复杂逻辑推演的结构化问题时,其能力仍有待提升。
- 人类智慧的价值: 评测结果甚至引发了让“人类博士生也来参与评估”的讨论,这再次凸显了人类在复杂问题解决上的独特价值。
- 未来的方向: 未来的AI发展,不能仅仅依赖于数据规模的扩大,更需要攻克在推理、逻辑和泛化能力上的瓶颈。
这项评测,无疑为AI模型的未来发展指明了方向。只有当AI真正掌握了这种深层次的推理能力,才能算得上是向 “通用人工智能(AGI)” 迈出了坚实的一步。
想了解更多详情,或查看完整榜单? 模型地址: https://huggingface.co/spaces/double-ai/FormulaOne-Leaderboard