前言
使用大模型 API 的成本由多个环节构成,不只是 token 单价本身。缓存未命中导致的重复计费、连接中断导致的响应丢失、以及定价本身的空间,都是实际影响账单的因素。
Poixe 在这三个方向上分别做了对应的优化。以下逐一说明。
一、缓存亲和性路由:减少重复的 token 计费
问题
主流模型提供商(Anthropic Claude、Google Gemini、OpenAI GPT 等)支持 Prompt Caching:当连续请求携带相同的前缀内容时,上游会缓存这部分 token,后续请求按缓存价格计费,通常为正常价格的 10% 左右。
但在 API 网关场景下,传统的负载均衡会将请求分散到不同渠道。第一次请求在渠道 A 建立的缓存,第二次请求被路由到渠道 B,缓存无法命中。请求被打散,缓存也就失效了。
方案
Poixe 上线了缓存亲和性路由(Cache Affinity Routing)。对于支持 Prompt Cache 的模型,系统会在一定时间窗口内将同一用户的请求固定路由到同一渠道,使上游缓存得以连续积累和命中。
窗口到期后,绑定自动解除,下次请求重新进入正常的权重分配流程。如果绑定的渠道在窗口期内发生错误(如限流、超时),系统会立即解除绑定并降级到常规负载均衡,不影响可用性。
效果
以携带长 System Prompt 的多轮对话为例,首次请求完整处理所有输入 token,后续请求的前缀部分命中缓存,按缓存价格计费。对于高频、长上下文的使用场景,token 费用的下降是直接可观的。
用户无需任何配置,系统对支持缓存的模型自动启用。
相关文档:提示词缓存(缓存亲和性路由)
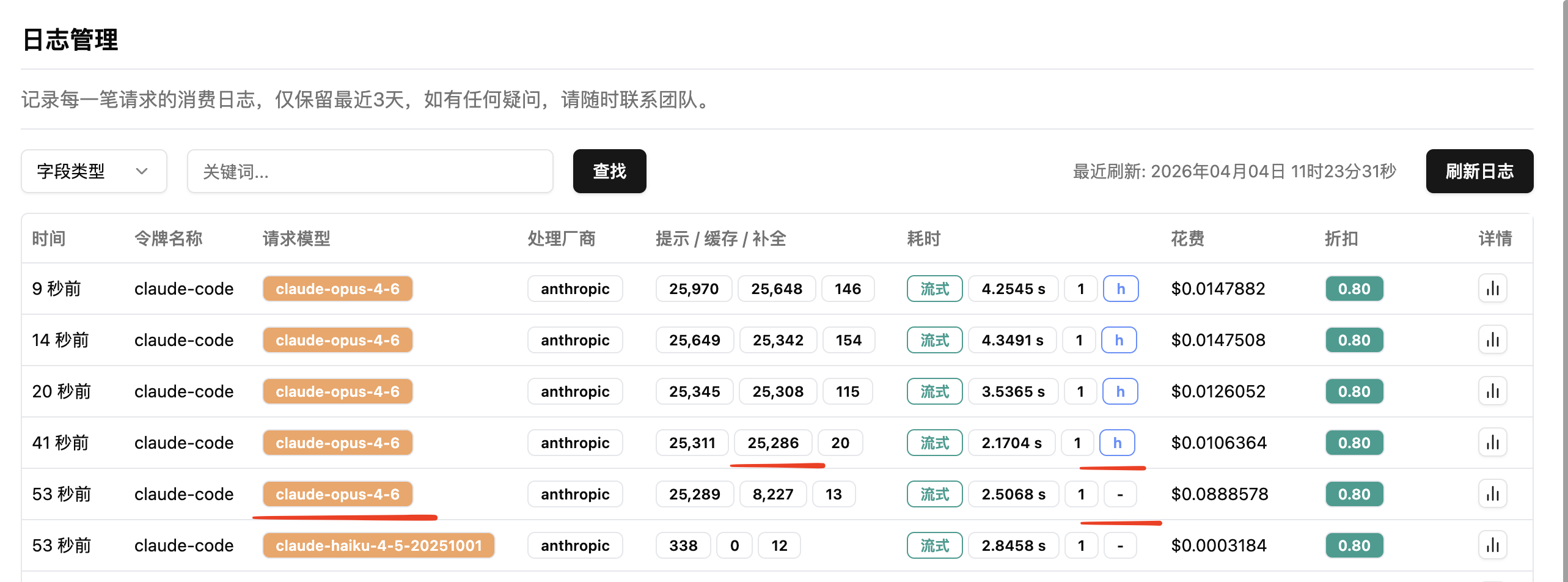
二、中断响应找回:避免因连接断开造成的重复计费
问题
AI 模型的推理请求通常耗时较长,尤其是长输出、复杂工具链或深度思考场景。在 API 网关的架构中,请求链路涉及客户端、CDN、网关、上游多个节点,任何一个环节的连接中断都可能导致客户端收不到响应。
关键在于:上游模型可能已经完成了推理并产生了计费,但响应结果在回传途中丢失了。如果用户因此重新发起请求,就会产生双倍的费用。
这种情况在非流式请求(stream=false)中尤为常见——响应是一次性返回的,连接断开意味着整个结果丢失。
方案
Poixe 提供了 Recoveries(中断响应找回)机制。当非流式请求发生连接中断时,系统会自动将该次请求的完整响应暂存,用户可以在事后通过接口找回结果,而不必重新发起请求。
找回流程:
- 系统检测到连接中断,自动暂存请求与响应数据
- 用户通过日志页面或 API 获取对应的
request_id - 调用
GET /v1/recoveries/{request_id}取回完整响应
暂存记录默认保留 3 天,到期自动清理。用户也可以主动删除。
效果
对于因网络波动、CDN 超时等原因导致的响应丢失,用户不再需要盲目重试。先查询是否有暂存记录,确认上游未完成后再重试,避免了不必要的重复计费。
相关文档:中断响应找回(Recoveries)
三、供应商入驻与折扣定价:从源头降低单价
背景
市场上存在大量闲置的 AI API 额度。企业采购了年度配额但用量不及预期,开发者测试完项目后额度仍有剩余,研究机构的账号配额存在富余——这些资源如果不被使用,就是纯粹的沉没成本。
机制
Poixe 通过供应商入驻机制回收这些闲置额度。持有 OpenAI、Anthropic、Gemini、Azure、DeepSeek 等平台 API 资源的供应商,可以将额度接入 Poixe 平台,由平台统一调度和分发。
供应商自主定价,平台负责流量分配、计费和结算。由于这些额度的边际成本低于官方直接采购价,最终面向用户的定价可以在官方价格基础上提供折扣。
效果
用户在调用相同模型、获得相同质量响应的前提下,实际支付的 token 单价低于直接向上游采购的价格。折扣幅度取决于具体模型和当前供应情况,用户可以在平台的模型定价页面查看实时价格。
供应商申请:供应商入驻
总结
三个方向,对应三种不同的成本来源:
| 成本来源 | 优化方式 | 机制 |
|---|---|---|
| 缓存未命中导致的重复 token 计费 | 缓存亲和性路由 | 渠道复用,提升 Prompt Cache 命中率 |
| 连接中断导致的响应丢失与重复请求 | 中断响应找回 | 自动暂存,事后取回 |
| token 单价本身 | 供应商入驻与折扣定价 | 回收闲置额度,降低采购成本 |
这些机制独立生效,叠加使用。用户不需要修改现有的调用方式,也不需要额外配置。
Poixe AI 官网:https://poixe.com