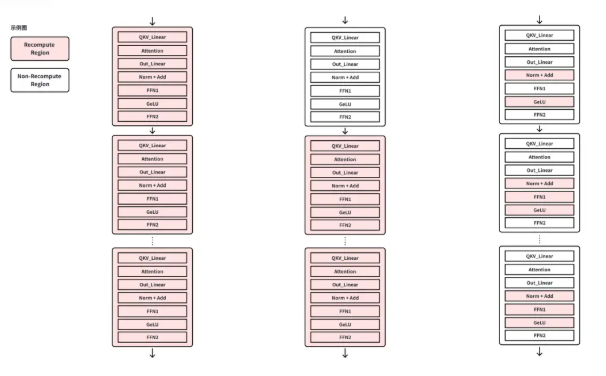
随着人工智能从单一的语言模型,向融合文本、图像、视频的多模态模型快速演进,算法工程师们在训练过程中面临着前所未有的挑战。复杂的训练流程、碎片化的工具链,成为了制约研发效率的关键瓶颈。
为解决这一难题,字节跳动宣布正式开源其内部研发的统一多模态训练框架——VeOmni。这款框架的推出,旨在为全球的AI研究者和开发者提供一个强大的工具,显著提升多模态模型的训练效率和性能。
VeOmni:三大“统一”核心理念
VeOmni框架由字节跳动的 Seed 团队与火山机器学习平台共同研发,其设计核心是实现三个关键的“统一”:
- 统一多模态: 一个框架支持多种类型的模型训练,无论是大规模语言模型、视觉语言模型,还是视频生成模型,都能轻松上手。
- 统一并行策略: 将多种混合并行策略整合到一个API中,开发者无需手动处理复杂的并行配置。
- 统一算力底座: 兼容不同的算力基础设施,确保训练流程的高效性和稳定性。
性能卓越:训练效率的质的飞跃
VeOmni框架通过一系列技术创新,实现了显著的性能优化,使其在实际训练中表现出色:
- 训练吞吐量大幅提升: 相比同类开源方案,VeOmni 的训练吞吐量提升了 40% 以上,极大地缩短了模型训练周期。
- 显存与计算双重优化: 框架采用独特的双优化策略,在确保显存充足的前提下,最大限度地减少了额外的计算开销。
- 多维并行体系: 支持多种并行原语,有效降低了训练过程中的显存峰值,让大规模模型的训练变得更加可行。
- 蒸馏加速: 内置多种前沿的蒸馏技术,能够显著减少模型推理所需的步骤和资源,从而加速模型的部署和商业应用。
开源:赋能AI生态,助力技术普惠
VeOmni框架的开源,不仅是字节跳动内部技术积累的一次对外分享,更体现了其对开源生态的承诺。它为广大的AI研究者和开发者提供了一个高效、强大的工具,解决了多模态训练中的痛点,将极大地推动多模态AI技术的普及和发展。
总结:
字节跳动开源的 VeOmni 框架,凭借其“三统一”的核心理念和卓越的性能优化,为多模态模型的训练提供了一个高效、统一的解决方案。其高达40%以上的训练吞吐量提升,无疑将成为AI领域的一大利器。这款框架的发布,不仅巩固了字节跳动在AI技术前沿的地位,也为整个行业的创新发展注入了新的活力。